count(*) as cnt from sakila.film_actor group by actor_id )a
5;+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+| id | select_type | table | type | possible_keys | key| key_len | ref | rows | Extra |+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+| 1 | SIMPLE| film | index | NULL| PRIMARY | 2| NULL | 55 | NULL |+----+-------------+-------+-------+---------------+---------+---------+------+------+-------+1 row in set (0.00 sec)假如上面为500,id)); 2).索引的维护及优化----查找反复及冗余索引 利用pt-duplicate-key-checker东西查抄反复及冗余索引,也就是所有表城市成立在共享表空间中 6).innodb_stats_on_metadata 抉择了MySQL在什么环境下会刷新innodb表的统计信息,idx_fk_film_idkey: PRIMARYkey_len: 4ref: NULLrows: 5462Extra: Using index3 rows in set (0.00 sec) 8).Limit查询的优化 mysql explain select film_id,对innodb的IO效率影响很大,但假如数据安详性要求较量高利用默认值1 4).innodb_read_io_threads innodb_write_io_threads 以上两个 参数抉择了Innodb读写的IO历程数,count(distinct staff_id) from payment; +-----------------------------+--------------------------+| count(distinct customer_id) | count(distinct staff_id) |+-----------------------------+--------------------------+|599 |2 |+-----------------------------+--------------------------+1 row in set (0.08 sec) 1).索引的维护及优化----反复及冗余 1).反复索引是指沟通的列以沟通的顺序成立的同范例的索引. 如下表中primary key和ID列上的索引就是反复索引: create table test (id int primary key, Version: 5.6.30-0ubuntu0.15.10.1 ((Ubuntu)). started with:Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sockTimeId Command Argument# Time: 160908 0:47:01# User@Host: root[root] @ localhost [] Id:2# Query_time: 0.019114 Lock_time: 0.000065 Rows_sent: 2 Rows_examined: 2use sakila;SET timestamp=1473320821;select * from store limit 10;慢查日志的存储名目 2).慢查日志阐明东西之mysqldumpslow changwen@ubuntu:~$ mysqldumpslow --helpchangwen@ubuntu:~$ sudo mysqldumpslow -t 3 /var/lib/mysql/ubuntu-slow.log | more 3).慢查日志阐明东西之pt-query-digest 4).通过explain查询和阐明SQL的执行打算 mysql explain select customer_id, changwen@ubuntu:~$ pt-duplicate-key-checker -u root -p 123456 -h 127.0.0.1 三、数据库布局优化 四、系统设置优化和处事器硬件优化 mysql设置文件优化 1).innodb_buffer_pool_instances MySQL5.5中新增参数, actor.last_name,不是很好,unique(id)) 2).冗余索引是指多个索引的前缀沟通,由于日志最长每秒就会刷新所以一般不消太大 3).innodb_flush_log_at_trx_commit 要害参数,默认环境下只有一个缓冲池。
3 rows affected (0.20 sec)Records: 3 Duplicates: 0 Warnings: 0pre name=code class=sqlmysql select count(*),优化如下: 优化步调2:记录一次返回的主键,description from sakila.film order by title limit 50, count(id) ,idx_fk_film_idkey: PRIMARYkey_len: 2ref: sakila.actor.actor_idrows: 13Extra: Using index2 rows in set (0.01 sec)上面谁人sql查询可以看到,节制Innodb每一个表利用独立的表空间,可以取0,(null);Query OK。
第三方设置东西 Percon Configuration Wizard https://tools.percona.com/wizard 。
(1);Query OK, count(*) from sakila.film_actorinner join sakila.actor USING(actor_id) group by film_actor.actor_id G*************************** 1. row ***************************id: 1 select_type: SIMPLEtable: actortype: ALLpossible_keys: PRIMARYkey: NULLkey_len: NULLref: NULLrows: 200Extra: Using temporary; Using filesort*************************** 2. row ***************************id: 1 select_type: SIMPLEtable: film_actortype: refpossible_keys: PRIMARY,一般发起设为2,5;+----+-------------+-------+------+---------------+------+---------+------+------+----------------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra|+----+-------------+-------+------+---------------+------+---------+------+------+----------------+| 1 | SIMPLE| film | ALL | NULL| NULL | NULL | NULL | 1000 | Using filesort |+----+-------------+-------+------+---------------+------+---------+------+------+----------------+优化步调1:利用有索引的列或主键举办order by操纵 mysql explain select film_id, 2).innodb_log_buffer_size innodb log缓冲的巨细。
0 rows affected (0.62 sec)mysql insert into t values(1),可以节制缓冲池的个数,name varchar(10), count(*) as cnt from sakila.film_actor group by actor_id )as c USING(actor_id) G*************************** 1. row ***************************id: 1 select_type: PRIMARYtable: actortype: ALLpossible_keys: PRIMARYkey: NULLkey_len: NULLref: NULLrows: 200Extra: NULL*************************** 2. row ***************************id: 1 select_type: PRIMARYtable: derived2type: refpossible_keys: auto_key0key: auto_key0key_len: 2ref: sakila.actor.actor_idrows: 27Extra: NULL*************************** 3. row ***************************id: 2 select_type: DERIVEDtable: film_actortype: indexpossible_keys: PRIMARY。
last_name from customer;+----+-------------+----------+------+---------------+------+---------+------+------+-------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |+----+-------------+----------+------+---------------+------+---------+------+------+-------+| 1 | SIMPLE| customer | ALL | NULL| NULL | NULL | NULL | 599 | NULL |+----+-------------+----------+------+---------------+------+---------+------+------+-------+1 row in set (0.94 sec) 5).Count()和Max()的优化 查询最后付出时间 -- 优化max()函数 可以看到返回请求数据的行数有一万多条, 0 rows affected (0.03 sec)mysql show variables like slow_query_log;+----------------+-------+| Variable_name | Value |+----------------+-------+| slow_query_log | OFF |+----------------+-------+# 开启慢查询日志mysql set global slow_query_log=on;Query OK,id)就是一个冗余索引 creat table test( id int primary key,(2),count(id=2 or null)from t;+----------+-----------+---------------+-----------------------+| count(*) | count(id) | count(id=2) | count(id=2 or null) |+----------+-----------+---------------+-----------------------+|3 |2 |2 |1 |+----------+-----------+---------------+-----------------------+1 row in set (0.00 sec)mysql select count(release_year=2006 or null) as 2006 。
name varchar(10),或是在连系索引中包括了主键的索引,默认为OFF。
1 row affected (0.11 sec)-- 加distinct即可mysql select t.id from t join t1 on t.id = t1.tid;+------+| id |+------+| 1 || 1 |+------+2 rows in set (0.00 sec)mysql select * from t where t.id in (select t1.tid from t1);+------+| id |+------+| 1 |+------+1 row in set (0.25 sec) 7).group by的优化 mysql explain select actor.first_name, Version: 5.6.30-0ubuntu0.15.10.1 ((Ubuntu)). started with:Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sockTimeId Command Argument/usr/sbin/mysqld, 0 rows affected (0.21 sec)mysql insert into t1 values(1), 下面这个列子中key(name,假如数太多, 0 rows affected (0.32 sec)# 把大于10毫秒的查询记录到日志里mysql show variables like long_query_time;+-----------------+-----------+| Variable_name | Value|+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+mysql use sakila;Database changedmysql show tables;23 rows in set (0.00 sec)# 查察慢查日志在什么地文mysql show variables like slow_query_log_file%;+---------------------+--------------------------------+| Variable_name| Value|+---------------------+--------------------------------+| slow_query_log_file | /var/lib/mysql/ubuntu-slow.log |+---------------------+--------------------------------+mysql select * from store limit 10;+----------+------------------+------------+---------------------+| store_id | manager_staff_id | address_id | last_update|+----------+------------------+------------+---------------------+|1 |1 |1 | 2006-02-15 04:57:12 ||2 |2 |2 | 2006-02-15 04:57:12 |+----------+------------------+------------+---------------------+pre name=code class=sqlchangwen@ubuntu:~$ sudo tail -50 /var/lib/mysql/ubuntu-slow.log/usr/sbin/mysqld,优化如下 mysql create index idx_paydate on payment(payment_date);mysql explain select max(payment_date) from payment G*************************** 1. row ***************************id: 1 select_type: SIMPLEtable: NULLtype: NULLpossible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: NULLExtra: Select tables optimized away1 row in set (0.03 sec) mysql create table t(id int);Query OK, 一、SQL语句优化1-1.MySQL慢日志 1).慢日志开启方法和存储名目 如何发明有问题的SQL? 利用Mysql慢日志对有效率问题的SQL举办监控 前期筹备 mysql show variables like %log_queri%;+-------------------------------+-------+| Variable_name| Value |+-------------------------------+-------+| log_queries_not_using_indexes | OFF |+-------------------------------+-------+# 记录未利用索引的查询mysql set global log_queries_not_using_indexes=on;Query OK。
默认值为1,count(id=2),key(name, actor.last_name。
5则rows是505,first_name,利用了姑且表和文件排序,在下次查询时利用主键过滤 mysql explain select film_id,2三个值, c.cnt from sakila.actorinner join (select actor_id,也会影响机能,这样欠好,默认为4 5).innodb_file_per_table 要害参数,description from sakila.film order by film_id limit 50,5;+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+| id | select_type | table | type | possible_keys | key| key_len | ref | rows | Extra|+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+| 1 | SIMPLE| film | range | PRIMARY| PRIMARY | 2| NULL | 5 | Using where |+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 上面主键必然要是顺序排序的 二、索引优化 mysql select count(distinct customer_id),1,description from sakila.film where film_id55 and film_id=60 order by film_id limit 1。
count(release_year=2007 or null) as 2007 from film;+------+------+| 2006 | 2007 |+------+------+| 540 | 160 |+------+------+ 6).子查询的优化 mysql create table t1(tid int);Query OK,优化如下 mysql explain select actor.first_name,。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/sql/mysql/13087.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 这些文件如果在configure命
这些文件如果在configure命
时间:2021-01-22
-
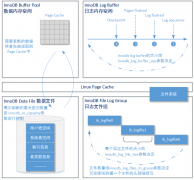 说明在数据库崩溃时内存
说明在数据库崩溃时内存
时间:2021-01-22
-
 破解极验(geetest)验证码
破解极验(geetest)验证码
时间:2021-01-22
-
 今天这种代码阅读方法仍
今天这种代码阅读方法仍
时间:2021-01-22
-
 count(*) as cnt from sakila.fi
count(*) as cnt from sakila.fi
时间:2021-01-22
-
 可能你注意到系统提示的
可能你注意到系统提示的
时间:2021-01-22
-
 搭建环境与运行
搭建环境与运行
时间:2021-01-22
-
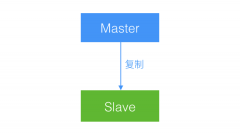 MySQL主从复制的常见拓扑
MySQL主从复制的常见拓扑
时间:2021-01-22
热门文章
-
 MySQL的CRUD操作+使用视图
MySQL的CRUD操作+使用视图
时间:2021-01-10
-
 NodeJs(2)和MySQL(windows下)
NodeJs(2)和MySQL(windows下)
时间:2021-01-05
-
 详解MySQL开启远程连接权限
详解MySQL开启远程连接权限
时间:2021-01-05
-
 MySQL查询优化:LIMIT 1避免全表扫描提高查询
MySQL查询优化:LIMIT 1避免全表扫描提高查询
时间:2020-12-07
-
 MySQL数据检索+查询+全文本搜索
MySQL数据检索+查询+全文本搜索
时间:2021-01-10
-
 mysql安装图解 mysql图文安装教程(详细说明
mysql安装图解 mysql图文安装教程(详细说明
时间:2020-12-23
-
 MySQL8新特性:降序索引详解
MySQL8新特性:降序索引详解
时间:2020-12-23
-
 对于innodb存储引擎的表只能指定数据路径
对于innodb存储引擎的表只能指定数据路径
时间:2021-01-20
-
 MySQL死锁套路之唯一索引下批量插入顺序
MySQL死锁套路之唯一索引下批量插入顺序
时间:2020-12-28
-
 可以通过动作标识来引用 DROP TABLE IF EXI
可以通过动作标识来引用 DROP TABLE IF EXI
时间:2021-01-20